
In computational linguistics,
coreference, sometimes written as co-reference is the concept which occurs when two or more words in the text
refers to the same person or thing or situation [1]. For e.g. FC Barcelona president Joan Laporta has warned Chelsea off star strike
Lionel Messi. This warning has generated discouragement in Chelsea. Here, “This warning” refers to the first sentence.
The goal of coreference resolution is
to determine the correct interpretation of the text or even to estimate the
relative importance of various mentioned subjects or pronouns and referring
expressions must be connected to the right individuals [7].
Humans naturally associate these
references together – however for a computer program it is difficult to
understand. Following are the types of coreference –
- Anaphora - "The
house is not for sale. We do not want to let it go."
- Cataphora - "We do not want to let it go. The house is not for sale."
- Exophora - "Spitting is not allowed here"
In this blog, we are mainly going to
focus on the anaphora. The anaphora is an expression whose meaning depends on
that of the other expression called the antecedent. In the above example, “the
house” is the antecedent and “it” is the anaphora.
The basic approaches for resolving
coreference involves finding mentions - Words that are potentially referring to
real world entities.
For e.g.
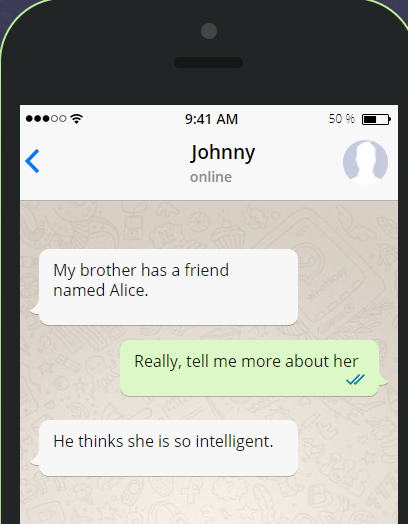
In the above conversation, mentions are
"My brother", "a friend
named Alice", "me”, "her”, "he", "she".
Mentions are generally detected by
recursively visiting the parse trees and choosing pronouns, noun phrases and
proper names [6].
Earlier approaches involved heuristic
approaches based on linguistic theories. For each mention and pair of mention,
we compute a set of features like syntactic (the gender of the two mentions
should be same) and semantic pragmatic (they should discuss about the same topic) constraints.
Then we find the most
likely antecedent for a mention if there exists based on these set of features.
These features are
generally handcrafted and there can be many such features. Hobbs [3] applied deepest first tree approach for finding the first mention that satisfies the given constraints in the syntactic parse tree.
Unsupervised learning
techniques adopted Bayesian models based on Latent Dirichlet
processes were also developed but the results turned out to be less
satisfactory.
Now comes the modern
NLP techniques like word vectors and neural networks. These approaches allow us
to learn a lot of hand-crafted features (machine learning) and reduce the
number of features while maintaining a good accuracy.
For e.g.
"Her is a
feminine pronoun and has more chances of referring to Alice than my brother
which is masculine"
This way we can define rules for our
model or we can represent each word in our vocabulary as a vector (word2vec) and let our
model train on a well-annotated corpus without supplying any prior information
about the gender.
Although the accuracy of the model
highly depends on the training corpus, since most of the NLP corpus are based
on news which are formal text. For training a chatbot,
however, they don't provide informal language texts which is generally expected
from it.
In fact, we can also define our own
text in the model but it would work on some mentions but not on others which
are less formal.
Now comes the state of
the art technique for resolving co-reference, that is none other than neural
networks. [4] introduces an end-to-end
coreference resolution model and it claims that it significantly outperforms all
previous work without using a syntactic parser or hand-engineered mention
detector. "The key idea is to directly consider all spans in a document as
potential mentions and learn distributions over possible antecedents for each."[4].
It also combines context knowledge for calculating spans.
[5] also uses neural network for
co-reference resolution. In this model, "some simple context information obtained by averaging word
vectors surrounding each mention is added. The first neural net gives a score for
each pair of a mention and a possible antecedent while a second neural net
gives a score for a mention having no antecedent (sometimes a mention is the
first reference to an entity in a text) [5]. Then simply comparing all these scores
together and taking the highest score to determine whether a mention has an
antecedent and which one it should be" [5].
References:
[1] https://en.wikipedia.org/wiki/Coreference
[2] https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3226856/
[3] Hobbs JR. Resolving pronoun references. Lingua. 1978;44(4):311–38. doi:10.1016/0024-3841(78)90006-2.
[4] End-to-end Neural Coreference Resolution
Kenton Lee
†
, Luheng He , Mike Lewis , and Luke Zettlemoyer arXiv:1707.07045 [cs.CL]
[5] https://medium.com/huggingface/state-of-the-art-neural-coreference-resolution-for-chatbots-3302365dcf30
[6] http://www.cs.upc.edu/~ageno/anlp/coreference.pdf
[7] “Speech and Language Processing: An introduction to natural language processing, computational linguistics, and speech recognition” by Daniel Jurafsky & James H. Martin
[7] “Speech and Language Processing: An introduction to natural language processing, computational linguistics, and speech recognition” by Daniel Jurafsky & James H. Martin
Comments
Post a Comment