In this post, I will talk about word embedding and their role in success of many deep learning models in natural language processing. Other interesting read related to this topic can be found in [1], [2].
 |
| Word Embedding obtained from English and German |
A word embedding is a representation of word W into an n-dimensional vector space (From words to real numbers).
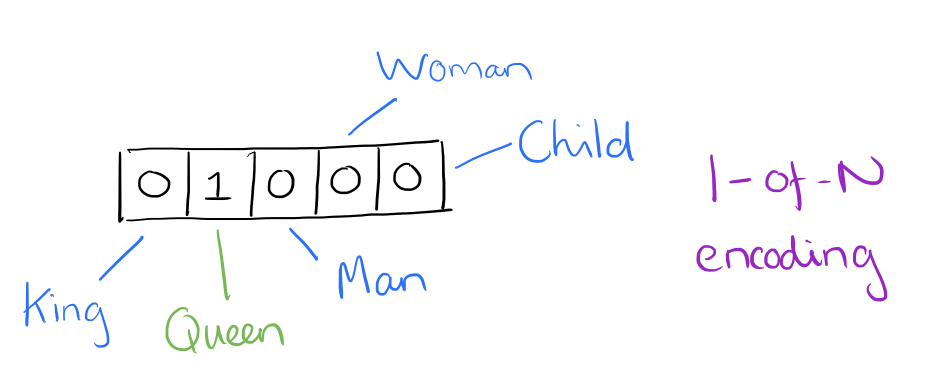 |
| Suppose there are only five words in our vocabulary king, queen, man, woman, child. Queen can be encoded as shown. |
Word embedding helps in efficient and expressive representation of words. Such representation helps in capturing semantic and syntactic similarities and are able to identify relationship between each other in a very simple manner.
 |
| Word Embedding capturing the gender relation. Arrows are mathematical vectors denoting the relationship |
How are word embedding generated ?
A word embedding matrix J is generated by training an unsupervised algorithm on a very large corpus and then multiplying word W with J . Thankfully, there are many popular models that provide us the matrix J to generate the word embedding. Two such models are Word2vec and GloVe.
Word2vec is a predictive model. It is implemented in two ways. Continuous Bag Of Words (CBOW) and skip-gram. In CBOW we have a window around some target word and then consider the words around it. We supply those words as input into our network and then use it to try to predict the target word. Skip-gram does the opposite, and try to predict the words that are in the window around that word.
GloVe is a count-based model that learn their vectors by essentially doing dimensionality reduction on the co-occurrence counts matrix. One can get to know more about them from [3] , [4], [5].
Word embeddings obtained from the previous step are used as input layer layer in CNN, LSTM for various tasks like sentence classification, sentence similarity. Thus, word embeddings have played pivotal role to improve the results of natural processing tasks.
References
[1]https://blog.acolyer.org/2016/04/21/the-amazing-power-of-word-vectors/
[2]http://blog.aylien.com/overview-word-embeddings-history-word2vec-cbow-glove/
[3]http://mccormickml.com/2016/04/27/word2vec-resources/#kaggle-word2vec-tutorial
[4] https://deeplearning4j.org/word2vec.html
[5] https://nlp.stanford.edu/pubs/glove.pdf
Word2vec is a predictive model. It is implemented in two ways. Continuous Bag Of Words (CBOW) and skip-gram. In CBOW we have a window around some target word and then consider the words around it. We supply those words as input into our network and then use it to try to predict the target word. Skip-gram does the opposite, and try to predict the words that are in the window around that word.
 |
| Word2vec archtecture |
GloVe is a count-based model that learn their vectors by essentially doing dimensionality reduction on the co-occurrence counts matrix. One can get to know more about them from [3] , [4], [5].
Word embeddings obtained from the previous step are used as input layer layer in CNN, LSTM for various tasks like sentence classification, sentence similarity. Thus, word embeddings have played pivotal role to improve the results of natural processing tasks.
References
[1]https://blog.acolyer.org/2016/04/21/the-amazing-power-of-word-vectors/
[2]http://blog.aylien.com/overview-word-embeddings-history-word2vec-cbow-glove/
[3]http://mccormickml.com/2016/04/27/word2vec-resources/#kaggle-word2vec-tutorial
[4] https://deeplearning4j.org/word2vec.html
[5] https://nlp.stanford.edu/pubs/glove.pdf
Comments
Post a Comment